
Artificial Intelligence (AI) is transforming industries by offering more efficient and scalable solutions. Two pivotal techniques driving these advancements are Low Rank Adaptation (LoRA) and quantization. These methods streamline the computational and memory demands of large AI models, enhancing their accessibility and efficiency without sacrificing performance. LoRA refines the fine-tuning process of large language models (LLMs) by incorporating low-rank matrices, which significantly reduces the number of trainable parameters.
Concurrently, quantization lowers the precision of numerical computations, resulting in faster inference and reduced memory usage. This article explores the mechanics, applications, and benefits of these transformative techniques, and introduces Quantization-Aware LoRA (QA-LoRA), which synergizes the advantages of both approaches.
Read Also : Recent Trends in AI: Shaping the Future of Technology
Low Rank Adaptation (LoRA)
What is LoRA?
Low Rank Adaptation (LoRA) is a technique designed to optimize the fine-tuning of large language models (LLMs) by reducing the number of trainable parameters. This is achieved by incorporating low-rank matrices into the model, allowing significant updates with minimal computational overhead.
How does LoRA work?
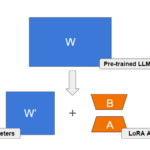
LoRA leverages the concept of low-rank matrices to efficiently adapt large models. Instead of updating all the parameters of a model, LoRA introduces trainable low-rank matrices (typically represented as A and B) that modify a smaller subset of the model’s parameters. This approach drastically reduces the number of parameters that need to be fine-tuned. For instance, in the case of GPT-3, LoRA can cut down the trainable parameters from 175 billion to merely 17.5 million.
The method involves decomposing a large weight matrix W into two smaller matrices A and B. During training, the weights of the pre-trained model are kept frozen, and only the parameters within these low-rank matrices are updated. This process ensures that the core structure and the knowledge embedded in the pre-trained model are preserved while adapting it to new tasks.
What are the applications and benefits of LoRA ?
– Efficiency: LoRA significantly reduces the computational burden, enabling faster adaptation of models even on less powerful hardware.
– Preservation of Knowledge: By keeping the core weights intact, LoRA maintains the pre-trained model’s original capabilities and understanding while allowing for specific task adaptations.
– Versatility: LoRA can be applied to various models, including those used in natural language processing (NLP) and image generation. For example, it has been used in Stable Diffusion models to adapt styles and characters without the need for full retraining.
Quantization
What is Quantization?
Quantization is a technique aimed at enhancing the efficiency of AI models by reducing the precision of the numerical values used in computations. This involves converting high-precision weights (such as 32-bit floating-point numbers) into lower precision formats (such as 8-bit integers).
How Does Quantization Work?
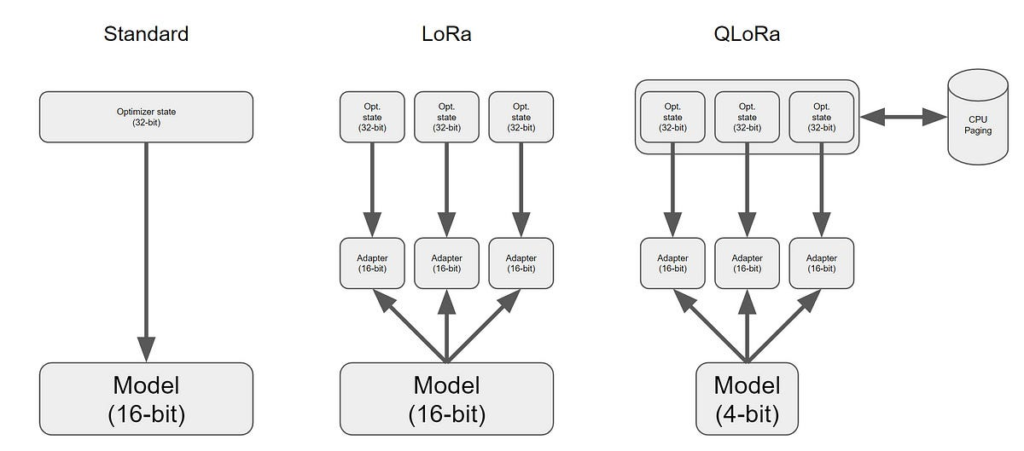
Quantization maps a large range of continuous values into a smaller set of discrete values. This process significantly reduces the memory footprint and accelerates the inference process. Techniques like QLoRA combine quantization with LoRA to enhance model performance while maintaining efficiency. This approach is crucial for deploying AI models on edge devices with limited computational resources.
Applications and benefits of Quantization
– Reduced Memory Usage: Quantization significantly decreases the memory required for storing model parameters by lowering the precision of weights.
– Faster Inference: The simpler arithmetic operations involved in lower-precision calculations make quantized models ideal for real-time applications.
– Energy Efficiency: By reducing computational load, quantization lowers power consumption, which is beneficial for battery-operated devices.
– Broad Applicability: Quantization can be applied to various models, making it suitable for a wide range of applications across different platforms.
QA-LoRA: Quantization-Aware Fine-Tuning
QA-LoRA extends the concept of LoRA by incorporating quantization into the fine-tuning process. This approach, called Quantization-Aware LoRA (QA-LoRA), fine-tunes and quantizes the model parameters simultaneously. This joint process not only reduces memory cost but also speeds up the fine-tuning process. The method utilizes INT4 data types for quantization, contrasting with QLoRA’s use of NF4, which can lead to better performance and lower perplexity.
How QA-LoRA Works QA-LoRA integrates quantization-aware training with low-rank adaptation. In traditional LoRA, low-rank matrices AAA and BBB are introduced to reduce the number of trainable parameters. QA-LoRA takes this a step further by incorporating quantization directly into the fine-tuning phase. This means that both the low-rank matrices and the quantization parameters are optimized together during training.
In practical terms, QA-LoRA modifies the base model weights into a lower precision format, such as INT4, which drastically reduces memory usage and computational requirements. During fine-tuning, the added low-rank matrices are also quantized. This dual optimization approach ensures that the fine-tuning process is highly efficient and that the resulting model remains lightweight and fast for inference.
Benefits of QA-LoRA
- Memory Efficiency: By reducing the precision of model parameters, QA-LoRA significantly lowers the memory footprint. This is particularly beneficial for deploying large language models (LLMs) on consumer-grade hardware with limited VRAM, such as GPUs with less than 24 GB of memory.
- Speed: The combined process of quantization and fine-tuning accelerates the adaptation of models to specific tasks. This is crucial for applications requiring regular updates or those that operate on rapidly changing datasets.
- Performance: Despite the reduced precision, QA-LoRA maintains high model performance. By using INT4 data types, QA-LoRA often achieves better perplexity scores compared to methods like QLoRA that use NF4 for quantization. This leads to models that are not only efficient but also effective in delivering high-quality results.
Comparison with QLoRA
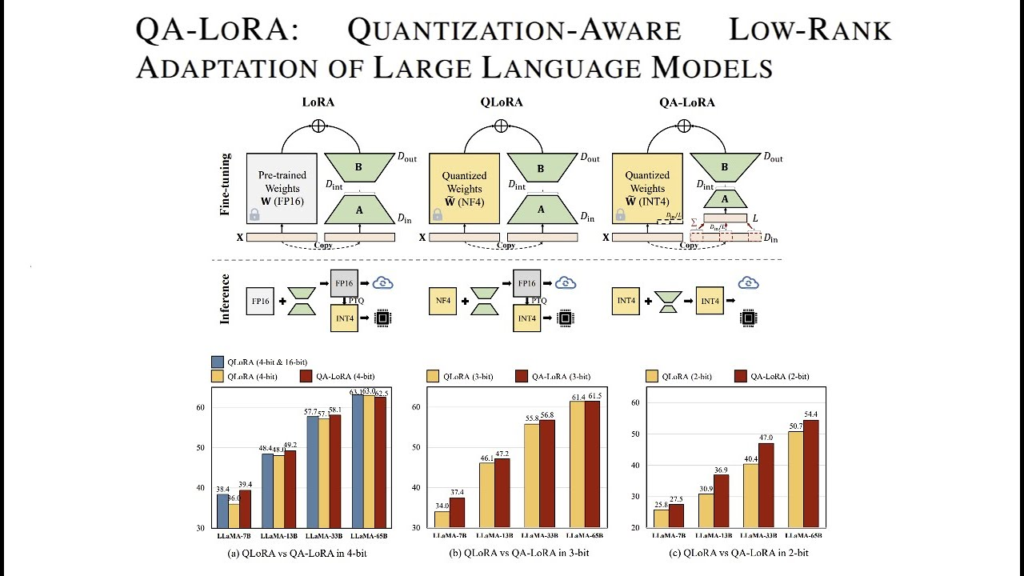
QLoRA is another technique that fine-tunes models using LoRA on top of quantized base models. However, QLoRA typically employs NF4 for quantization, which, while effective, can introduce complexities in terms of inference speed and performance. NF4, being a compressed float representation, may not be as optimized for fast computations as INT4.
QA-LoRA addresses some of the limitations of QLoRA by:
- Using INT4 quantization, which is more straightforward and often faster than NF4.
- Allowing the entire model, including both the base and the low-rank matrices, to be quantized simultaneously, which simplifies the deployment and inference phases.
- Achieving comparable or better performance with a simpler and more efficient quantization strategy.
Practical Implementation and Challenges
Implementing QA-LoRA involves several steps, including the initialization of low-rank matrices, setting up quantization parameters, and ensuring stability during training. One practical challenge is managing the trade-off between quantization precision and model performance. While lower precision (such as INT4) reduces memory and computational load, it can also risk losing some model accuracy. QA-LoRA addresses this by carefully balancing the precision of different parts of the model, ensuring optimal performance without significant degradation.
In summary, QA-LoRA offers a robust solution for efficiently fine-tuning and deploying large language models. By combining the strengths of LoRA and quantization, it provides a scalable, high-performance approach to adapting AI models for various applications. This makes it a valuable tool for developers and researchers aiming to optimize AI systems within constrained computational environments.
Paving the Future of AI with LoRA and Quantization
LoRA and quantization are transformative techniques in the field of AI, addressing critical challenges of efficiency, scalability, and performance in large language models. By significantly reducing the computational and memory overhead required for training and deploying AI models, these methods make advanced AI capabilities accessible even on limited hardware. QA-LoRA, the integration of quantization with LoRA, takes these benefits a step further by fine-tuning and quantizing simultaneously, ensuring high performance while maintaining low resource consumption. As AI continues to advance, the adoption of techniques like LoRA and quantization will be crucial in pushing the boundaries of what AI can achieve, fostering innovation across diverse sectors and applications.
For further reading and detailed technical insights, you can explore research papers and resources available on arXiv, Microsoft Research, Papers With Code and the Kaitchup.



